This is a project by Eva Forsbom for the courses Object Oriented Software Development (teacher: Folke Bengtsson) and Applied Automata Theory for Language Engineering (teacher: Torbjörn Lager) at Uppsala University, Language Engineering Programme, Autumn 1999.
The RuleCompiler is a Java application for compiling rules for a Brill tagger into the regular expression format used in XFST (Xerox Finite-State Tools). Currently it supports only context rules.
Disclaimer: It is one of my first Java programs, and the first with a graphical user interface, so bear with me. (It is horrendously ugly, and while I have not encountered any disastrous bug yet, it is certainly not error-proof. You are welcome to try it, but do not blame me if something goes wrong.)
The original part-of-speech Brill tagger by Eric Brill tags a text incrementally. The words are looked up in a lexicon and assigned tags. Words that are not found are assigned the most frequent tag, often a noun tag. After that, a number of lexical rules are applied that correct som mistakes from the previous round. A sample lexical rule could be
Next, the context rules are applied. They could be of the format
This usually gives a good result, if the instantiated rules are applied in a certain order. However, Brill taggers are rather slow, and a possible way of speeding them up is to represent the tagger steps as finite state transducers. In XFST you build such transducers by constructing regular expressions. So, if these rules could be represented as regular expressions that were applied one after the other, it should be possible to get a fast Brill tagger, and this is what this application is all about.
I have only concerned myself with the context rules, so far, but the rule format is similar for the lexical rules, so it should not be to difficult to incorporate them later. In that case I have to find a better solution than hard-coding a kind of symbol table in the parser. But there is a beginning for everything.
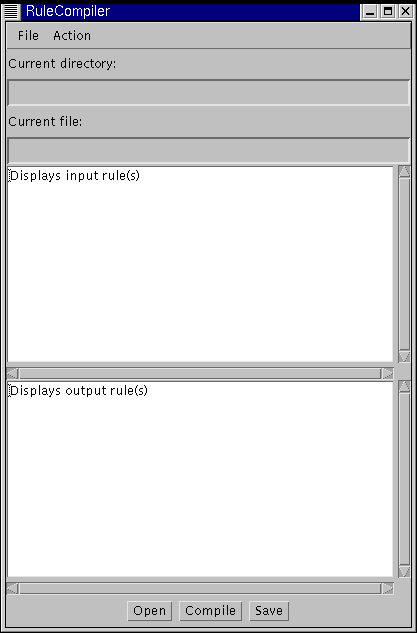
When you start the application you are presented with the following start screen, where you can open a rule file, compile and optionally save the converted file. (There's nothing stopping you opening another file either, unfortunately, but I assume you are a cooperative user.)
Menu options on the File menu include Open, Save and Exit. The only option on the Action menu is Compile. For each of these options there is also a corresponding button (the window closing button for Exit).
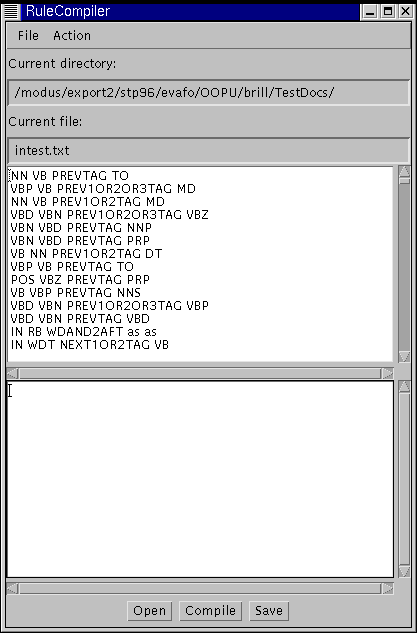
When you choose one of the options Open and Save, a file dialog opens so you can choose or name a file of your choice. It is a standard FileDialog from the Java library. On opening a rule file, a message is shown in the top text area while the file is loaded. The content of the rule file is then displayed in the same text area, as shown in the picture below.
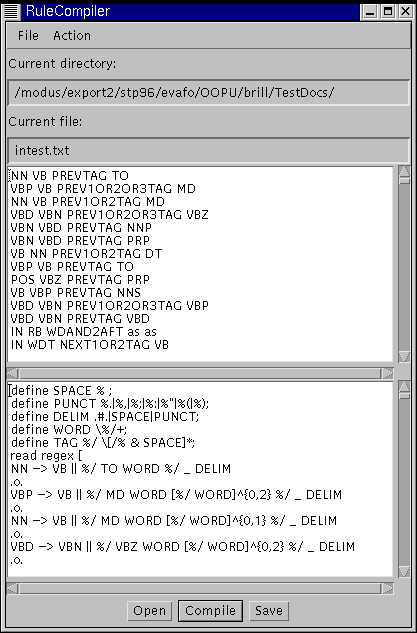
The main part of the application, though, lies in the compilation of the rules. You compile them by choosing Action -> Compile, or clicking Compile. A piece of cake for you, with the computer doing all the hard work.
The result of the compilation is displayed in the bottom text area:
If you are satisfied with the result, you need only click Save and name a file to store it. Otherwise, you can try compiling another rule file. It has to be a file, though. You cannot paste rules into the text area and compile them.
Supposing you are not compiling too many rules, you could then feed this saved file into XFST and get a transducer which changes tags in a tagged input text given a certain context.
Since this was also an exercise in applying UML descriptions of the application (UML being Unified Modelling Language), I used an evaluation copy of a CASE tool called ObjectPlant, for the Macintosh. (CASE stands for Computer-Aided Software Engineering.) With this tool you can create object models, use cases, state diagrams and event tracing. It also offers reversed engineering facilities (which was very practical in my case, since I did not really had the time to go to deeply into the specifics of the tool).
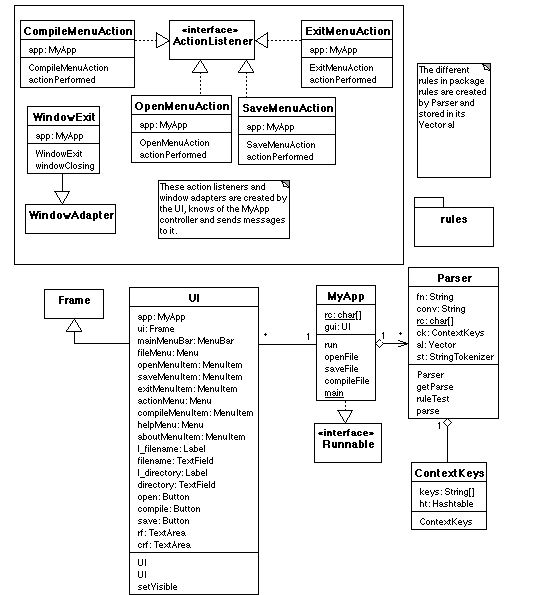
Below, you find a design class diagram (from the object model window in ObjectPlant). I found it a bit tricky to draw all the lines I wanted, so it is a bit simplified. The package rules is just represented as a package. I chose to do so, since all classes in the package are derived from the Template class via the ContextTemplate class, and they have all their methods and most of their attribute in common, so they do not contribute much to the understanding of associations between classes in this diagram. They are documented more carefully in the API documents created by the javadoc tool.
I did not bother to describe any use cases, since this is a very limited application. However, one possible use case could be named Compile rules, and in that case, it is pretty well described in the section Graphical User Interface above.
Neither did I do any system contracts or any collaboration diagrams, though I think at least the collaboration diagrams could have helped me solve some of the hard-coding. But since I had to start coding before I had done the more detailed planning, I saw no reason doing it afterwards.
As it turned out, the rules package is more or less up to scratch (there ought to be a NotARuleException) while the Parser and MyApp classes need a lot more fixing. They are also documented in API documents, though I would not want to use them as APIs.
To test the performance of this application, I used a file of 1,202 actual context rules taken from Eric Brill's tagger package. (That is the file showing in the screen dumps above.) The compilation took about a minute or less on a Linux client. I also tried to feed it into XFST, but the compilation to a transducer took roughly 3 to 4 hours on the server (which has more RAM than the clients), and the resulting transducer only accepted the string aa. This is a bit strange, since I also tested the rules (i.e. 26 templates) one by one with a suitable sentence, and there was no problem then. (However, I have changed some rules slightly after I did that, and have only tested some of them again, so I have to go through them again to be sure.) The result is also strange in the sense that all rules use the replacement operator, and transducers representing that operator should accept all strings, only changing them in the prescribed way. So the result is bewildering.
It seems as if it is only possible to compile the regular expressions i XFST, then it would be possible to build a very fast Brill tagger.